





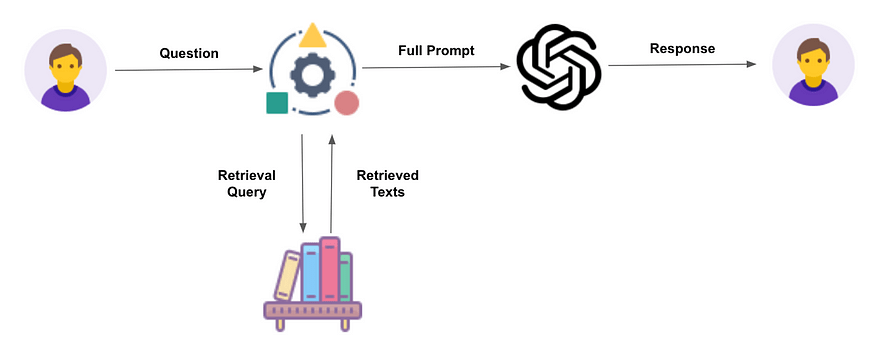
Retrieval-augmented generation, a promising approach in natural language processing, combines the power of retrieval and generative models to enhance the quality and relevance of the generated text. By leveraging pre-existing knowledge or external sources, retrieval-augmented generation enables systems to produce more accurate, diverse, and contextually appropriate responses.
This blog post will teach you seven effective techniques to boost retrieval-augmented generation.
What is Retrieval-Augmented Generation and How Can We Boost Its Performance
Retrieval augmented generation is a method that combines two important components: retrieval models and generative models. Using existing knowledge or external sources helps improve the quality of the generated text. In simple terms, retrieval models help find relevant information from a large dataset, while generative models create new text based on that information.
This valuable approach enables systems to produce more accurate and contextually appropriate responses. By understanding how retrieval-augmented generation works and how these two components interact, we can develop better conversational agents, question-answering systems, and content-generation tools.
It’s an exciting field with great potential for enhancing natural language processing capabilities.
Techniques To Boost Retrieval Augmented Generation
Clean your data
RAG connects the capabilities of an LLM to your data. Your data needs to be clearer in substance or layout, or else your system will suffer. If you’re using data with conflicting or redundant information, your retrieval will struggle to find the right context.
When it does, the generation step performed by the LLM may be suboptimal. Say you’re building a chatbot for your startup’s help docs and find it is not working well. First, you should look at the data you are feeding into the system.
Are topics broken out logically? Are topics covered in one place or many separate places? If you, as a human, can’t easily tell which document you need to look at to answer common queries, your retrieval system won’t be able to either.
Query Expansion and Reformulation
Query expansion techniques aim to enhance the relevance of retrieved information by expanding the initial query with additional terms or synonyms. This helps to retrieve a more comprehensive set of relevant documents or information. Reformulating the query based on user feedback or contextual information can also improve retrieval precision.
Semantic Search and Entity Recognition
Semantic search techniques utilize semantic relationships and context to improve information retrieval accuracy. By understanding the meaning and intent behind the query or context, these methods can retrieve more relevant information. Entity recognition techniques identify specific entities mentioned in the query or context, allowing for more targeted and precise retrieval.
Experiment with your chunking approach.
Chunking up the context data is a core part of building a RAG system. Frameworks abstract the chunking process and allow you to get away without thinking about it. But you should think about it. Chunk size matters.
You should explore what works best for your application. In general, smaller chunks often improve retrieval but may cause generation to suffer from a lack of surrounding context. There are a lot of ways you can approach chunking. The one thing that doesn’t work is approaching it blindly.
This post from PineCone lays out some strategies to consider. I have a test set of questions. I approached this by running an experiment. I looped through each set once with a small, medium, and large chunk size and found small to be best.
Try meta-data filtering
A very effective strategy for improving retrieval is to add meta-data to your chunks and then use it to help process results. The date is a common meta-data tag because it allows you to filter by recency. Imagine you are building an app that allows users to query their email history. More recent emails will likely be more relevant. But we don’t know that they’ll be the most similar from an embedding standpoint to the user’s query. This brings up a general concept to remember when building RAG: similar ≠ relevance.
You can append the date of each email to its meta-data and then prioritize the most recent context during retrieval. LlamaIndex has a built in class of Node Post-Processors that help with exactly this.
Align the input query with the documents
LLMs and RAGs are powerful because they offer the flexibility of expressing your query in natural language, thus lowering the entry barrier for data exploration and more complex tasks. (Learn here how RAGs can help generate SQL code from plain English instructions).
Sometimes, however, a misalignment appears between the input query the user formulates in a few words or a short sentence and the indexed documents, often written in longer sentences or even paragraphs.
Pre-training and Transfer Learning
Pre-training and transfer learning have proven to be effective techniques in retrieval-augmented generation. Pre-trained models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), have succeeded remarkably in various natural language processing tasks.
These models are trained on large-scale corpora, learning contextual representations that capture rich semantic information. By fine-tuning these pre-trained models on retrieval-augmented generation tasks, we can adapt them to specific retrieval and generation objectives, resulting in improved performance.
Transfer learning techniques enable the transfer of knowledge learned from one task or domain to another, leveraging the pre-trained models’ capabilities. By incorporating pre-training and transfer learning, retrieval-augmented generation systems can benefit from better contextual understanding, more accurate retrieval, and more coherent and relevant generation.
Benefits Of Boosting The Retrieval-Augmented Generation
Boosting retrieval-augmented generation (RAG) offers several benefits that can significantly improve the performance and capabilities of natural language processing systems. Here are some key benefits of enhancing RAG:
Enhanced Accuracy
The accuracy of retrieval models can be improved by incorporating effective techniques to boost RAG, such as query expansion and neural information retrieval. This leads to more precise and relevant information retrieval, resulting in higher-quality generated responses. Users can expect more accurate answers to their queries and better contextual understanding in conversations.
Improved Relevance
RAG techniques help retrieve and generate more contextually relevant responses. Cross-modal approaches, for example, enable the integration of multiple modalities, such as text and images, allowing systems to generate responses that are not only accurate but also contextually grounded. This enhances the user experience by providing more relevant and meaningful information.
Increased Diversity
Techniques like reinforcement learning and adversarial training can promote diversity in generated responses. Reinforcement learning encourages the generation of diverse and creative outputs, reducing the problem of repetitive or generic responses.
Adversarial training helps develop responses resistant to adversarial modifications, increasing the range of possible reactions and improving system robustness.
Contextual Understanding
Pre-training and transfer learning techniques enable retrieval-augmented generation systems to have a better contextual understanding. By leveraging pre-trained language models, such as BERT and GPT, the systems can capture rich semantic information and adapt it to specific retrieval and generation tasks.
This results in more coherent and contextually appropriate responses, enhancing the conversational experience.
Knowledge Enrichment
Integrating knowledge graphs into RAG systems enables access to structured knowledge, enhancing retrieval and generation capabilities. Knowledge graph integration facilitates entity linking, knowledge-aware generation, and graph-based retrieval, allowing the systems to provide more comprehensive and informative responses.
This benefits applications like question-answering and content generation, where accurate and structured information is crucial.
Robustness and Resilience
Applying adversarial training techniques to RAG models increases their resilience to adversarial attacks or perturbations. This enhances system robustness, ensuring that the models can handle challenging scenarios and adversarial queries effectively.
Robust systems are more reliable, providing consistent and trustworthy responses even with adversarial inputs.
Conclusion
Retrieval-augmented generation(RAG) is a powerful approach that combines information retrieval and natural language generation techniques to produce coherent and contextually relevant text. These models can generate high-quality content across various applications and use cases by integrating external knowledge sources into the generation process. By continuously advancing and refining these techniques, researchers and practitioners can unlock the full potential of retrieval-augmented generation, creating high-quality, contextually relevant, and engaging content for a wide range of applications.

As the editor of the blog, She curate insightful content that sparks curiosity and fosters learning. With a passion for storytelling and a keen eye for detail, she strive to bring diverse perspectives and engaging narratives to readers, ensuring every piece informs, inspires, and enriches.



